As a quick refresher, you can extract a vector of the observations for any particular variable from the dataframe as follows: famuss$[variable name]. For example:
# extract the age variablefamuss$age# store the age variable as a new object called "age"age <- famuss$age
Part 1: distributions
A “frequency distribution” is a summary that shows how frequently each value of a variable occurs. This summary is computed differently depending on the variable type.
Categorical variables
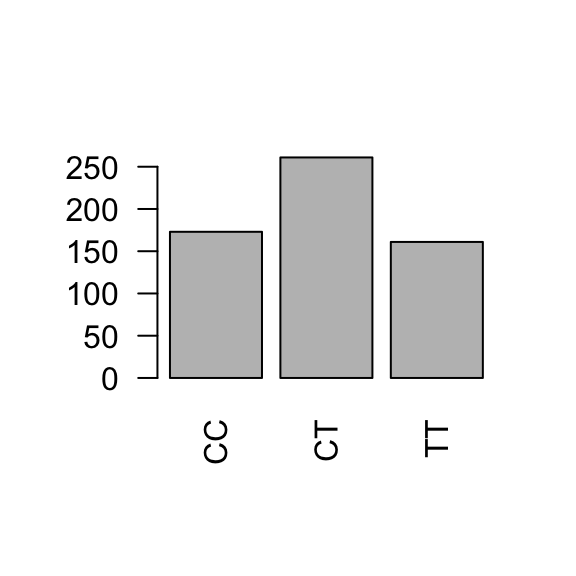
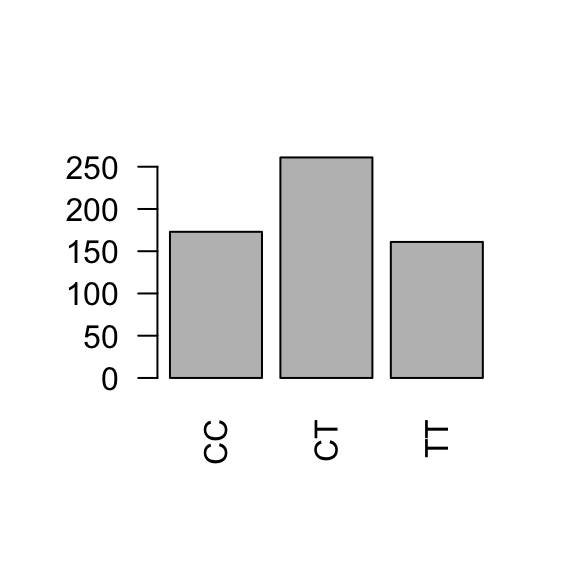
For categorical variables, table(...) will tabulate counts of the number of occurrences of each unique value (category). This is the frequency distribution and it can be shown in either counts or proportions.
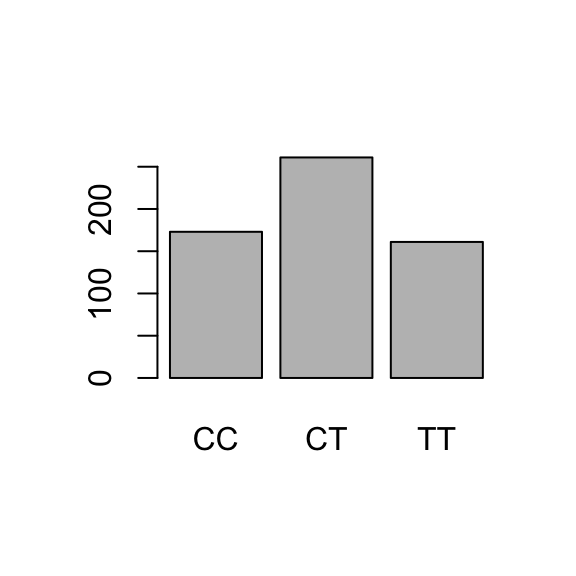
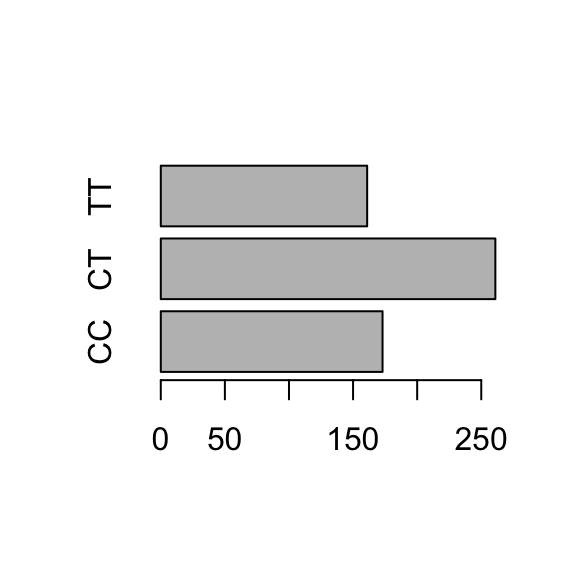
# retrieve genotypegenotype <- famuss$genotype# frequency distribution (counts)table(genotype)
genotype
CC CT TT
173 261 161
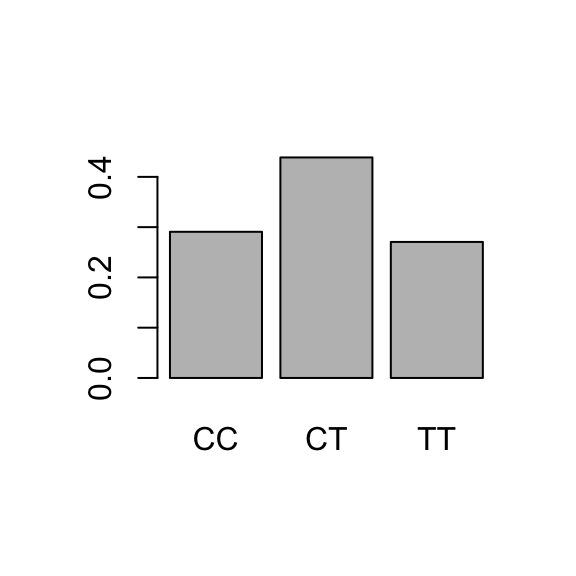
# frequency distribution (proportions)table(genotype) |>proportions()
genotype
CC CT TT
0.2907563 0.4386555 0.2705882
Barplots provide simple visualizations of categorical frequency distributions. Barplots may show either counts or proportions; it is only a difference of scale.
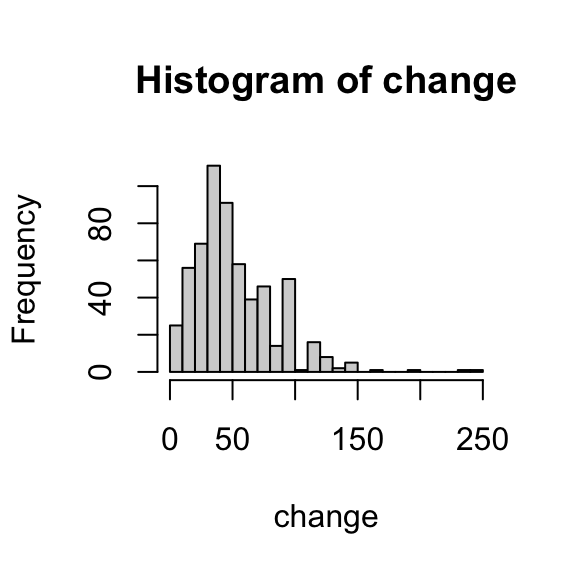
You can control the binning using the breaks = ... argument. If you provide one number, R will do its best to get close to that number; if you provide a vector, R will make bins with those values as endpoints.
Selecting an appropriate number of bins is a bit subjective; you want to try and capture the shape while smoothing out unnecessary detail.
Your turn
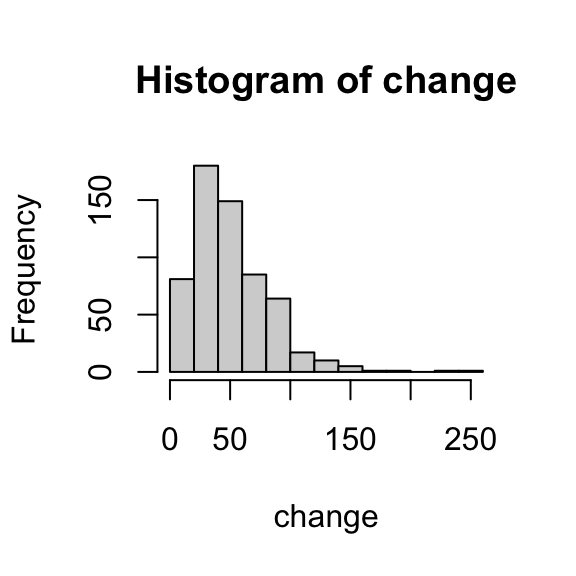
Using the histogram of nondominant arm strength change from the previous “your turn” exercise, tinker with the binning until you find a setting that you feel captures the shape of the distribution well.
If you finish the above and have a few minutes, pick one additional numeric variable and construct a histogram. Is the distribution skewed or symmetric? How many modes does it have?
# choose another variable# construct histogram
Part 2: summary statistics
Most common measures of center and spread have dedicated functions in R. We’ll review these below.
Measures of center
Means and medians are very straightforward to compute:
# average agemean(age)
[1] 24.40168
# median age (middle value)median(age)
[1] 22
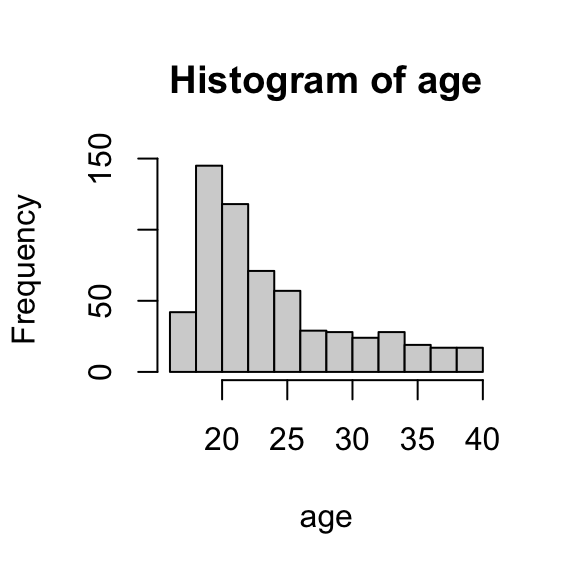
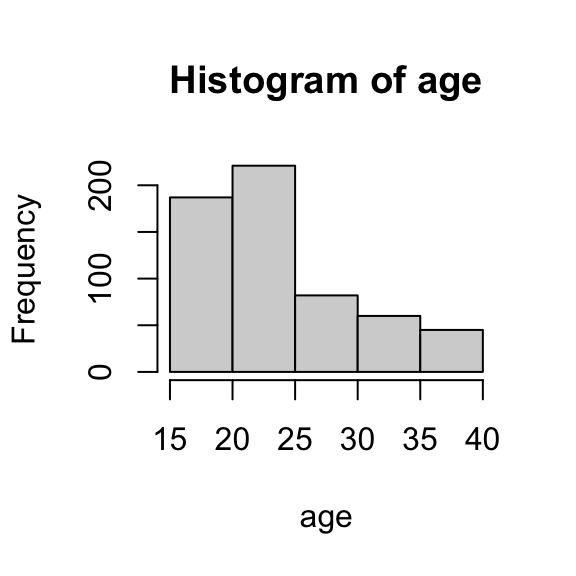
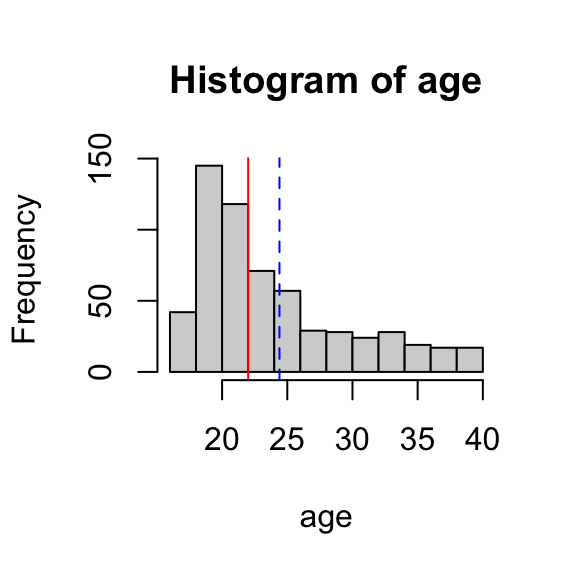
Which one do you use? That depends on the shape of the distribution. In this case, age is a little right-skewed, so the median may capture the center a little better. Take a moment to locate the mean and median on the histogram below and consider whether you agree.
# plot mean and median on top of histogramhist(age)abline(v =22, col ='red', lty =1) # ignore thisabline(v =24.4, col ='blue', lty =2) # ignore this too
Your turn
Extract the bmi variable from the FAMuSS data.
compute the mean
compute the median
Discuss with your neighbor: which (if either) is the better choice?
Solution
# extract bmibmi <- famuss$bmi# a. compute meanmean(bmi)
[1] 24.40108
# b. compute medianmedian(bmi)
[1] 23.35
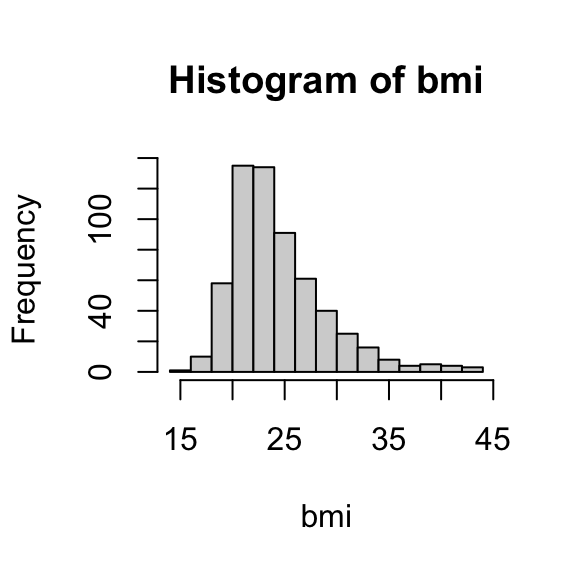
# histogramhist(bmi)
The distribution is fairly symmetric, and both measures are quite close, so either statistic (mean or median) is a good choice.
Percentiles and min/max
Percentiles are computed using the quantile() function:
# 20th percentile of agequantile(age, probs =0.2)
20%
19
# 60th percentile of agequantile(age, probs =0.6)
60%
24
The probs = ... argument specifies which percentile R will calculate.
Minima and maxima can be computed with min() and max(), respectively:
# minimum agemin(age)
[1] 17
# maximum agemax(age)
[1] 40
Your turn
Using the bmi variable from the FAMuSS data, compute the minimum, maximum, and quartiles:
min (0th percentile)
1st quartile (25th percentile)
median (50th percentile)
3rd quartile (75th percentile)
max (100th percentile)
Solution
# minmin(bmi)
[1] 15.504
# quartilesquantile(bmi, probs =0.25)
25%
21.295
quantile(bmi, probs =0.5)
50%
23.35
quantile(bmi, probs =0.75)
75%
26.6245
# maxmax(bmi)
[1] 43.758
As a shortcut, if you want to inspect all common measures of location and center – the five-number summary plus the mean – the summary(...) function will do just that.
# all common location/center measuressummary(age)
Min. 1st Qu. Median Mean 3rd Qu. Max.
17.0 20.0 22.0 24.4 27.0 40.0
Your turn
Compute the 5-number summary for bmi using summary() and compare with your answers to the previous “your turn” exercise.
Solution
# all common location/center measuressummary(bmi)
Min. 1st Qu. Median Mean 3rd Qu. Max.
15.50 21.30 23.35 24.40 26.62 43.76
Measures of spread
The following functions return common measures of spread for numeric variables:
range(...) returns the range (min, max)
IQR(...) returns the interquartile range (middle 50% of data)
var(...) returns the variance (average squared distance of observations from mean)
sd(...) returns the standard deviation (average distance of observations from mean)
# age rangerange(age)
[1] 17 40
# interquartile range of agesIQR(age)
[1] 7
# variance of agevar(age)
[1] 33.79966
# standard deviation of agesd(age)
[1] 5.813748
Which one to choose? It depends on the distribution: if there are large outliers, IQR is a better choice; otherwise, standard deviation is conventional. In this case, there are no age outliers (you can check the histogram above from Part 1), so standard deviation is the way to go.
Your turn
Determine and compute an appropriate measure of spread for BMI.
Solution
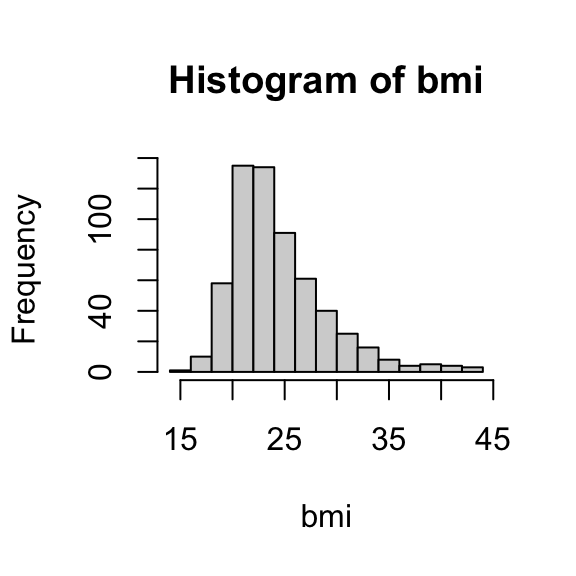
# histogram of bmihist(bmi)
# measure of spreadsd(bmi)
[1] 4.57662
There are no obvious outliers, so standard deviation is the way to go here.