| mean | sd | n | se |
|---|---|---|---|
| 5.043 | 1.075 | 3179 | 0.01906 |
Constructing interval estimates to attain a specified coverage rate
Under simple random sampling:
| mean | sd | n | se |
|---|---|---|---|
| 5.043 | 1.075 | 3179 | 0.01906 |
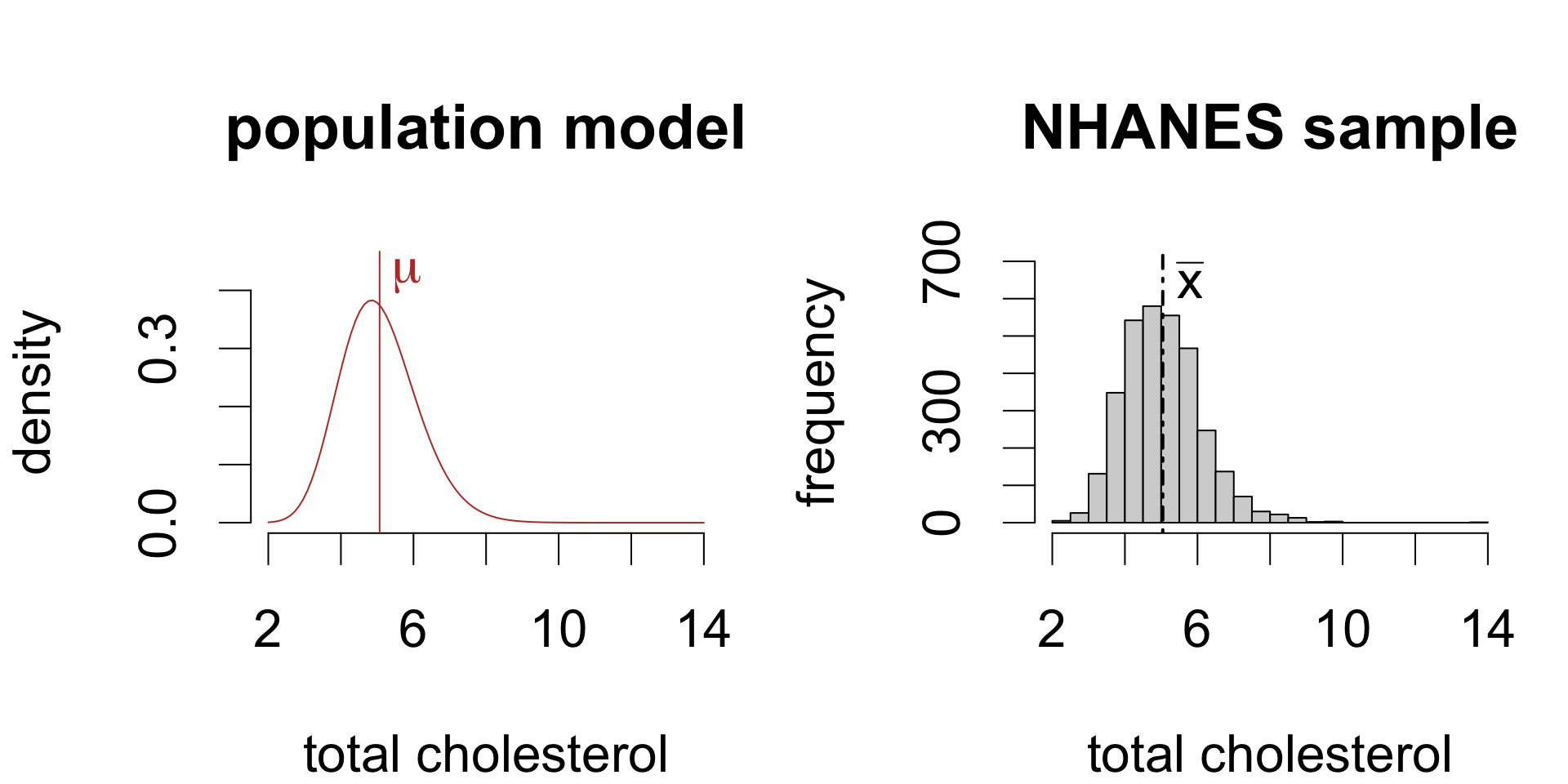
The mean total HDL cholesterol among the U.S. adult population is estimated to be 5.043 mmol/L (SE 0.0191).
A common interval estimate for the population mean is: ˉx±2×SE(ˉx)whereSE(ˉx)=(sx√n)
The mean total cholesterol among U.S. adults is estimated to be between 5.005 and 5.081 mmol/L.
Two related questions:
Consider the statistic:
T=ˉx−μsx/√n(estimation errorstandard error)
The sampling distribution of T is well-approximated by a tn−1 model whenever either:
OR

The area under the density curve between any two values (a,b) gives the proportion of random samples for which a<T<b.
(proportion of area between a,b)=(proportion of samples where a<T<b)
The area under the density curve between any two values (a,b) gives the proportion of random samples for which a<T<b.
(proportion of area between a,b)=(proportion of samples where a<T<b)
The area under the density curve between any two values (a,b) gives the proportion of random samples for which a<T<b.
(proportion of area between a,b)=(proportion of samples where a<T<b)
The area under the density curve between any two values (a,b) gives the proportion of random samples for which a<T<b.
(proportion of area between a,b)=(proportion of samples where a<T<b)
The area under the density curve between any two values (a,b) gives the proportion of random samples for which a<T<b.
(proportion of area between a,b)=(proportion of samples where a<T<b)
The area under the density curve between any two values (a,b) gives the proportion of random samples for which a<T<b.
(proportion of area between a,b)=(proportion of samples where a<T<b)
So where did that 2 come from in the margin of error for our interval estimate?
ˉx±2×SE(ˉx)
Well:
0.94=P(−2<T<2)=P(−2<ˉx−μsx/√n<2)=P(ˉx−2×SE(ˉx)<μ<ˉx+2×SE(ˉx)⏟interval covers population mean)
For 94% of all random samples, the interval covers the population mean.
So the number 2 determines the proportion of samples for which the interval covers the mean, known as its coverage.
The sample size determines the exact shape of the t model through its ‘degrees of freedom’ n−1. This changes the areas slightly.
The exact coverage quickly converges to just over 95% as the sample size increases.
| n | coverage |
|---|---|
| 4 | 0.8607 |
| 8 | 0.9144 |
| 16 | 0.9361 |
| 32 | 0.9457 |
| 64 | 0.9502 |
| 128 | 0.9524 |
| 256 | 0.9534 |

Consider a slightly more general expression for an interval for the mean:
ˉx±c×SE(ˉx)
The number c is called a critical value. It determines the coverage.
The so-called “empirical rule” is that:
P(−2<T<2)=1−2×P(T>2)
Look at how the areas add up so that: P(T>2)=0.03 Moreover: P(T<2)=1−0.03=0.97

So the critical value 2 is actually the 97th percentile of the sampling distribution of T.
To engineer an interval with a specific coverage, use the pth quantile where:
p=[1−(1−coverage2)] In R:
# coverage 95% using t quantile
coverage <- 0.95
q.val <- 1 - (1 - coverage)/2
crit.val <- qt(q.val, df = 20 - 1)
crit.val[1] 2.093024The effect of increasing/decreasing coverage on the quantile is:
Precision refers to how wide or narrow the interval is.
Precision depends on every component of the margin of error:
By contrast, coverage depends only on the critical value used.
Interval estimates constructed to achieve a specified coverage are called “confidence intervals”; the coverage is interpreted and reported as a “confidence level”.
# ingredients
cholesterol.mean <- mean(cholesterol)
cholesterol.sd <- sd(cholesterol)
cholesterol.n <- length(cholesterol)
cholesterol.se <- cholesterol.sd/sqrt(cholesterol.n)
crit.val <- qt(1 - (1 - 0.95)/2, df = cholesterol.n - 1)
# interval
cholesterol.mean + c(-1, 1)*crit.val*cholesterol.se[1] 5.005566 5.080310With 95% confidence, the mean total cholesterol among U.S. adults is estimated to be between 5.0056 and 5.0803 mmol/L.
The general formula for a confidence interval for the population mean is
ˉx±c×SE(ˉx)
where c is a critical value, obtained as a quantile of the tn−1 model and chosen to ensure a specific coverage.
The “common” interval estimate for the mean is actually an approximate 95% confidence interval:
ˉx±2×SE(ˉx)
captures the population mean μ for roughly 95% of random samples
replacing 2 with a tn−1 quantile allows the analyst to adjust coverage
the tn−1 model is an approximation for the sampling distribution of ˉx−μSE(ˉx)
Interval interpretation:
With [XX]% confidence, the mean [population parameter] is estimated to be between [lower bound] and [upper bound] [units].
Artificially simulating a large number of intervals provides an empirical approximation of coverage.
This is also a handy way to remember the proper interpretation:
If I made a lot of intervals from independent samples, 95% of them would ‘get it right’.

STAT218





