This series of exercises uses BRFSS survey data on health-related attributes of a sample of 60 U.S. adults. Following the prompts are a series of simple analyses. Each prompt requires you to utilize or interpret some part of the analysis.
The content and scope of the questions below are representative of the actual final. Moreover, the exam similarly is divided into parts focusing on analyzing specific relationships, and the number of questions within each part is comparable (4-6 questions per part). However, the final differs in two key respects: each part pertains to a different case study (i.e., they don’t all use the same dataset) and it is longer (30 questions across six case studies).
[L2] Is this observational or experimental data? Explain.
# load dataload('data/brfss2.RData')# preview general healthhead(brfss)
# A tibble: 6 × 5
genhlth gender age wtdesire weight
<fct> <fct> <int> <int> <int>
1 very good m 45 225 265
2 excellent m 24 150 150
3 excellent m 47 150 137
4 good f 26 125 159
5 very good f 33 125 145
6 very good f 28 120 125
Solution
This is observational data because there is no researcher intervention.
Part 1
This part pertains mostly to the self-rated general health variable: participants rated their general health as excellent, very good, good, fair, or poor. The last two categories have been combined in the data analysis shown.
[L1] What type of variable is genhlth?
Solution
Ordinal: it is categorical because its values are qualitative and values are ordered because, e.g., good exceeds fair.
[L6] Construct and interpret a 95% confidence interval for the proportion of U.S. adults who report being in excellent health.
Then, the CI is \(0.2833 \pm 2\times 0.0582\), which gives \((0.1669, 0.3997)\).
With 95% confidence, an estimated 16.69-39.97% of U.S. adults consider themselves to be in excellent health.
[L7] Do the data provide evidence of an association between self-reported general health and gender? If so, which rating/gender most accounts for the association?
excellent very good good fair or poor
m 13 8 6 2
f 4 10 11 6
Solution
\(\frac{13}{29}\) men and \(\frac{4}{31}\) women, or 44.8% and 12.9%, respectively, report being in excellent health.
[L8] Estimate the relative odds that a man reports being in excellent health compared with a woman. Provide a 95% confidence interval and interpret the interval in context.
excellent very good good fair or poor
m 13 8 6 2
f 4 10 11 6
Solution
Rewrite the table as:
excellent
other.rating
m
13
16
f
4
27
Then, the odds for men are \(\frac{13}{16}\), the odds for women are \(\frac{4}{27}\), so the odds ratio is \(\hat{\omega} = \frac{13/16}{4/27} = 5.48\).
For the interval:
The standard error for the log odds ratio is \(SE(\log(\hat{\omega})) = \sqrt{\frac{1}{13} + \frac{1}{16} + \frac{1}{4} + \frac{1}{27}} = 0.653\).
So the confidence interval for the log odds ratio is \(\log(5.48) \pm 2\times 0.653 = (0.3951, 3.0071)\).
Exponentiating endpoints yields an interval for the odds ratio of \((1.48, 20.23)\).
With 95% confidence, men are between 1.48 and 20.23 times more likely than women to report being in excellent health.
Part 2
Consider now the relationship between self-reported general health and desired weight loss.
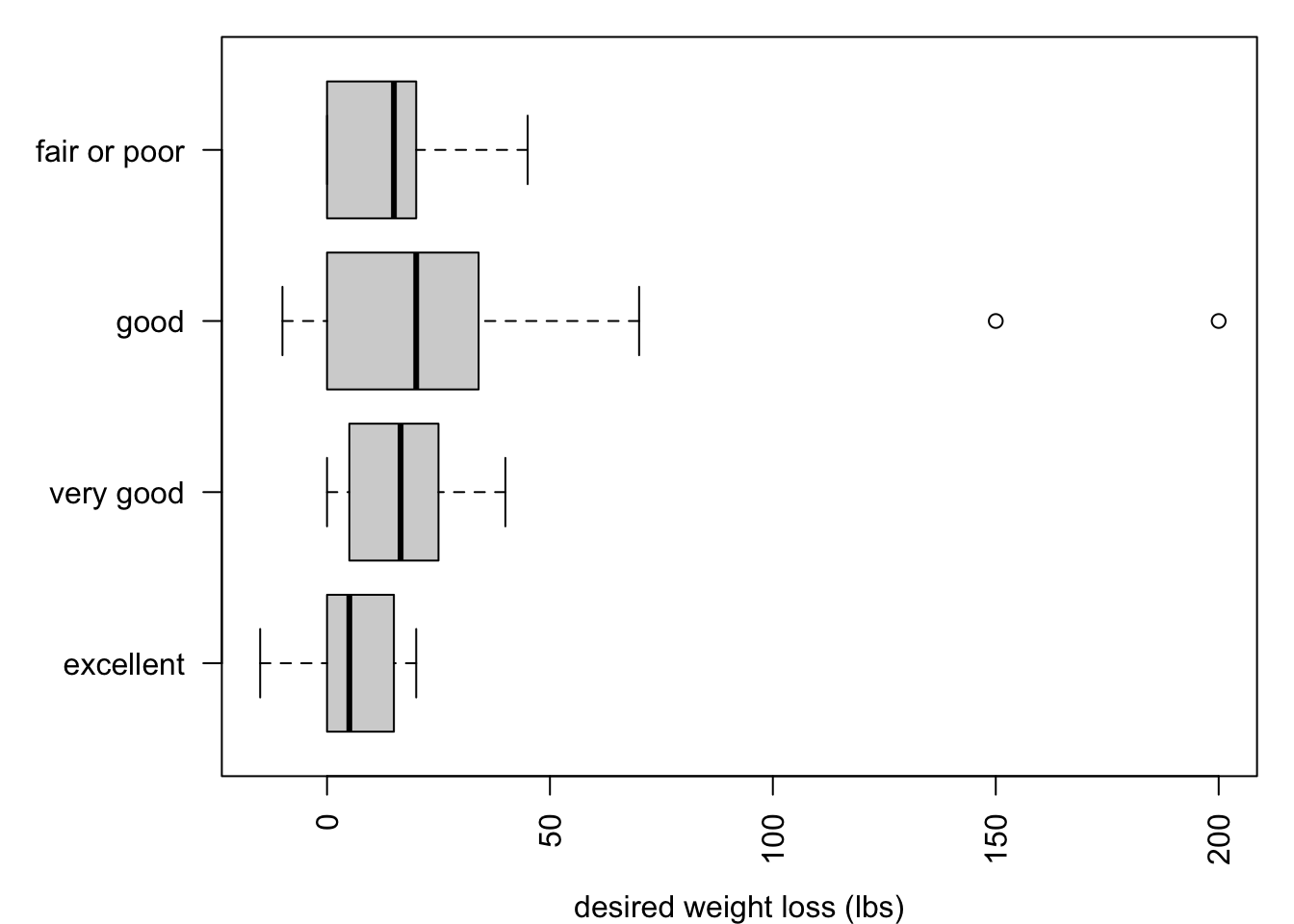
# plot desired weight loss by health categorypar(mar =c(4, 6, 1, 1))boxplot(weight - wtdesire ~ genhlth, data = brfss,horizontal = T, las =2, ylab =NULL,xlab ='desired weight loss (lbs)')
[L9] Do the data provide evidence at the 5% level that mean desired weight loss differs according to self-reported general health categories?
Df Sum Sq Mean Sq F value Pr(>F)
genhlth 3 7395 2465 2.353 0.0818 .
Residuals 56 58657 1047
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Solution
No, the data do not provide evidence that mean desired weight loss differs by self-reported general health (F = 2.35 on 3 and 56 df, p = 0.0818).
[L9] Estimate the mean desired weight loss among U.S. adults who rate themselves in excellent general health. Provide a 95% confidence interval.
# estimated group meanslibrary(emmeans)emmeans(fit, specs =~ genhlth) |>confint(adjust ='bonferroni')
genhlth emmean SE df lower.CL upper.CL
excellent 5.53 7.85 56 -14.73 25.8
very good 16.56 7.63 56 -3.13 36.2
good 34.47 7.85 56 14.21 54.7
fair or poor 14.38 11.40 56 -15.16 43.9
Confidence level used: 0.95
Conf-level adjustment: bonferroni method for 4 estimates
Solution
The mean desired weight loss among U.S. adults who rate themselves as being in excellent general health is estimated to be 5.53lbs; with 95% confidence, this figure is estimated to be between a weight gain of 14.73lbs and a weight loss of 25.8lbs.
[L9] Based on the data and at the 5% significance level, U.S. adults in which general health groups wish to lose weight on average?
# estimated group meansemmeans(fit, specs =~ genhlth) |>confint(adjust ='bonferroni')
genhlth emmean SE df lower.CL upper.CL
excellent 5.53 7.85 56 -14.73 25.8
very good 16.56 7.63 56 -3.13 36.2
good 34.47 7.85 56 14.21 54.7
fair or poor 14.38 11.40 56 -15.16 43.9
Confidence level used: 0.95
Conf-level adjustment: bonferroni method for 4 estimates
Solution
Good only.
The conclusion of a 5% level two-sided test of \(H_0: \mu_i = 0\) can be inferred based on whether the 95% intervals span zero. Only the good category has an interval estimate for mean desired weight loss that is strictly positive.
[L9] The output below shows the result of the Kruskal Wallis test comparing desired weight loss across groups defined by self-reported general health assessment. Why might this test be more appropriate, and does the conclusion differ?
# nonparametric alternative to anovakruskal.test(weight - wtdesire ~ genhlth,data = brfss)
Kruskal-Wallis rank sum test
data: weight - wtdesire by genhlth
Kruskal-Wallis chi-squared = 6.0081, df = 3, p-value = 0.1112
Solution
The “good” group exhibits more variability than the others with respect to desired weight loss and includes two very large outliers. While the conclusions do not differ at the 5% level, they would at the 10% level.
Part 3
Consider now the relationship between gender and desired weight loss.
[L4] Construct an approximate 95% confidence interval for the mean desired weight loss among U.S. adults.
Right-skewed and unimodal, with a few large outliers.
[L5] Does the data seem to satisfy assumptions for a \(t\) test?
Solution
It’s questionable. The sample size is large enough that the \(t\)-test may work fine, but the outliers are concerning and may affect results.
[L4] Do the data provide evidence (at the 5% level) that the typical U.S. adult wishes to lose weight? Identify which test below is most appropriate and report the result in context following conventional style.
# a few t testst.test(brfss$weight - brfss$wtdesire, mu =0, alternative ='greater')
One Sample t-test
data: brfss$weight - brfss$wtdesire
t = 4.2172, df = 59, p-value = 4.311e-05
alternative hypothesis: true mean is greater than 0
95 percent confidence interval:
10.99824 Inf
sample estimates:
mean of x
18.21667
t.test(brfss$weight - brfss$wtdesire, mu =0, alternative ='less')
One Sample t-test
data: brfss$weight - brfss$wtdesire
t = 4.2172, df = 59, p-value = 1
alternative hypothesis: true mean is less than 0
95 percent confidence interval:
-Inf 25.43509
sample estimates:
mean of x
18.21667
# a few nonparametric testswilcox.test(brfss$weight - brfss$wtdesire, mu =0, alternative ='greater')
Wilcoxon signed rank test with continuity correction
data: brfss$weight - brfss$wtdesire
V = 867.5, p-value = 9.799e-08
alternative hypothesis: true location is greater than 0
wilcox.test(brfss$weight - brfss$wtdesire, mu =0, alternative ='less')
Wilcoxon signed rank test with continuity correction
data: brfss$weight - brfss$wtdesire
V = 867.5, p-value = 1
alternative hypothesis: true location is less than 0
Solution
Here we want to use the ‘greater’ alternative since a positive value for \(\mu\) means that actual weight exceeds desired weight. The nonparametric test is the better choice here (see previous solution) but either is acceptable.
The data provide evidence that the typical U.S. adult wishes to lose weight (signed rank test, p < 0.0001).
[L5] Do the data provide evidence (at the 5% level) that typical desired weight loss differs between men and women? Identify which test below is most appropriate and report the result in context following conventional style.
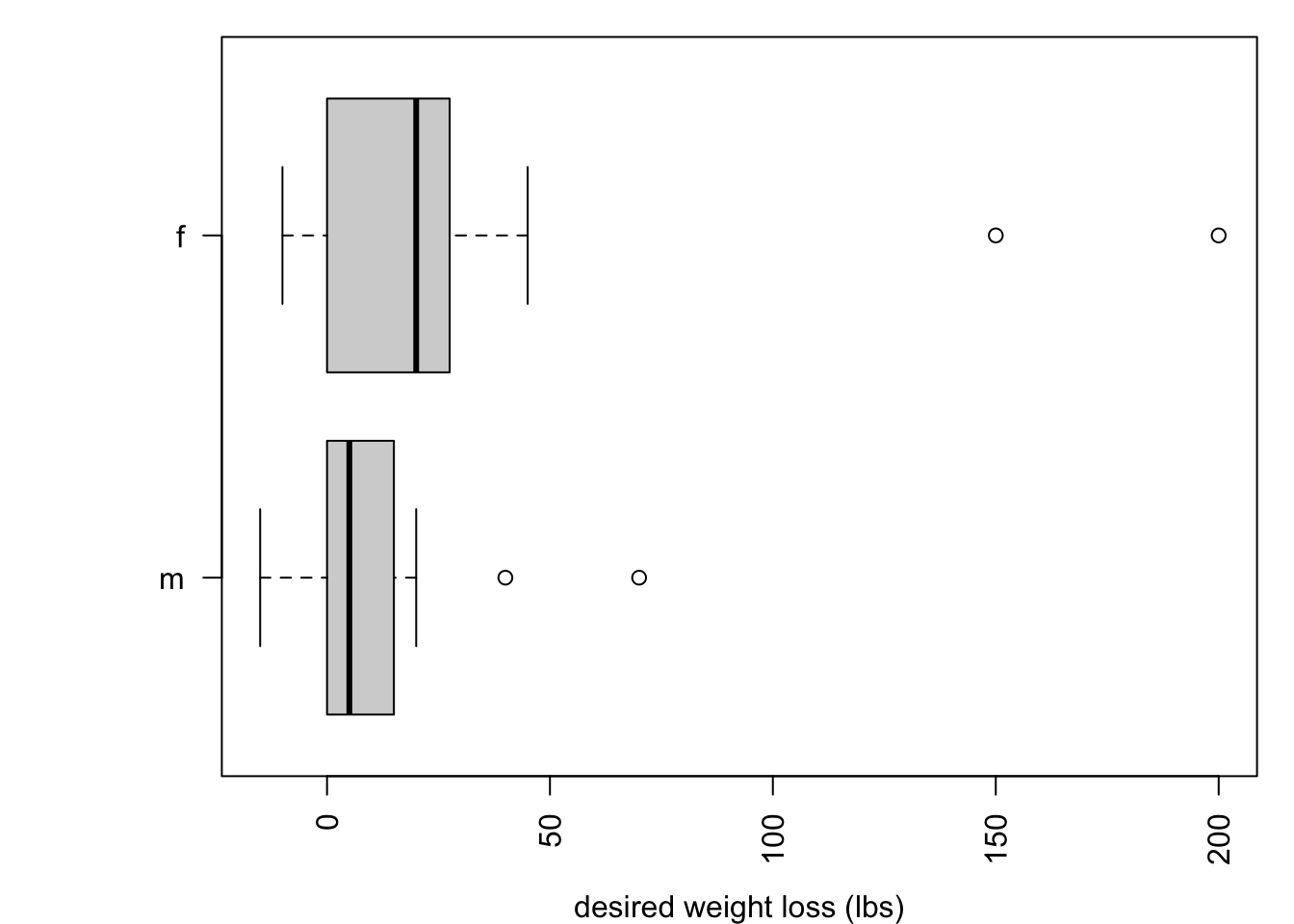
# plot desired weight loss by genderpar(mar =c(4, 6, 1, 1))boxplot(weight - wtdesire ~ gender, data = brfss,horizontal = T, las =2, ylab =NULL,xlab ='desired weight loss (lbs)')
# t test for difference by gendert.test(weight - wtdesire ~ gender, data = brfss)
Welch Two Sample t-test
data: weight - wtdesire by gender
t = -2.048, df = 38.875, p-value = 0.04735
alternative hypothesis: true difference in means between group m and group f is not equal to 0
95 percent confidence interval:
-33.4685580 -0.2066366
sample estimates:
mean in group m mean in group f
9.517241 26.354839
# nonparametric alternativewilcox.test(weight - wtdesire ~ gender, data = brfss)
Wilcoxon rank sum test with continuity correction
data: weight - wtdesire by gender
W = 288.5, p-value = 0.01587
alternative hypothesis: true location shift is not equal to 0
Solution
The nonparametric test is more appropriate owing to the outliers.
The data provide evidence that mean desired weight loss differs by gender (rank sum test, p = 0.0159).
Part 4
This part pertains to the relationship between weight and age.
[L10] Interpret the correlation between weight and age in context.
# correlation between age and weightcor(brfss$age, brfss$weight)
[1] 0.09502067
Solution
There is no linear relationship between weight and age.
Questions 17-20 refer to the following output.
# linear model fitfit <-lm(weight ~ age, data = brfss)summary(fit)
Call:
lm(formula = weight ~ age, data = brfss)
Residuals:
Min 1Q Median 3Q Max
-68.744 -29.545 -8.087 17.796 228.828
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 159.5339 19.9751 7.987 6.45e-11 ***
age 0.3145 0.4327 0.727 0.47
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 49.23 on 58 degrees of freedom
Multiple R-squared: 0.009029, Adjusted R-squared: -0.008057
F-statistic: 0.5284 on 1 and 58 DF, p-value: 0.4702
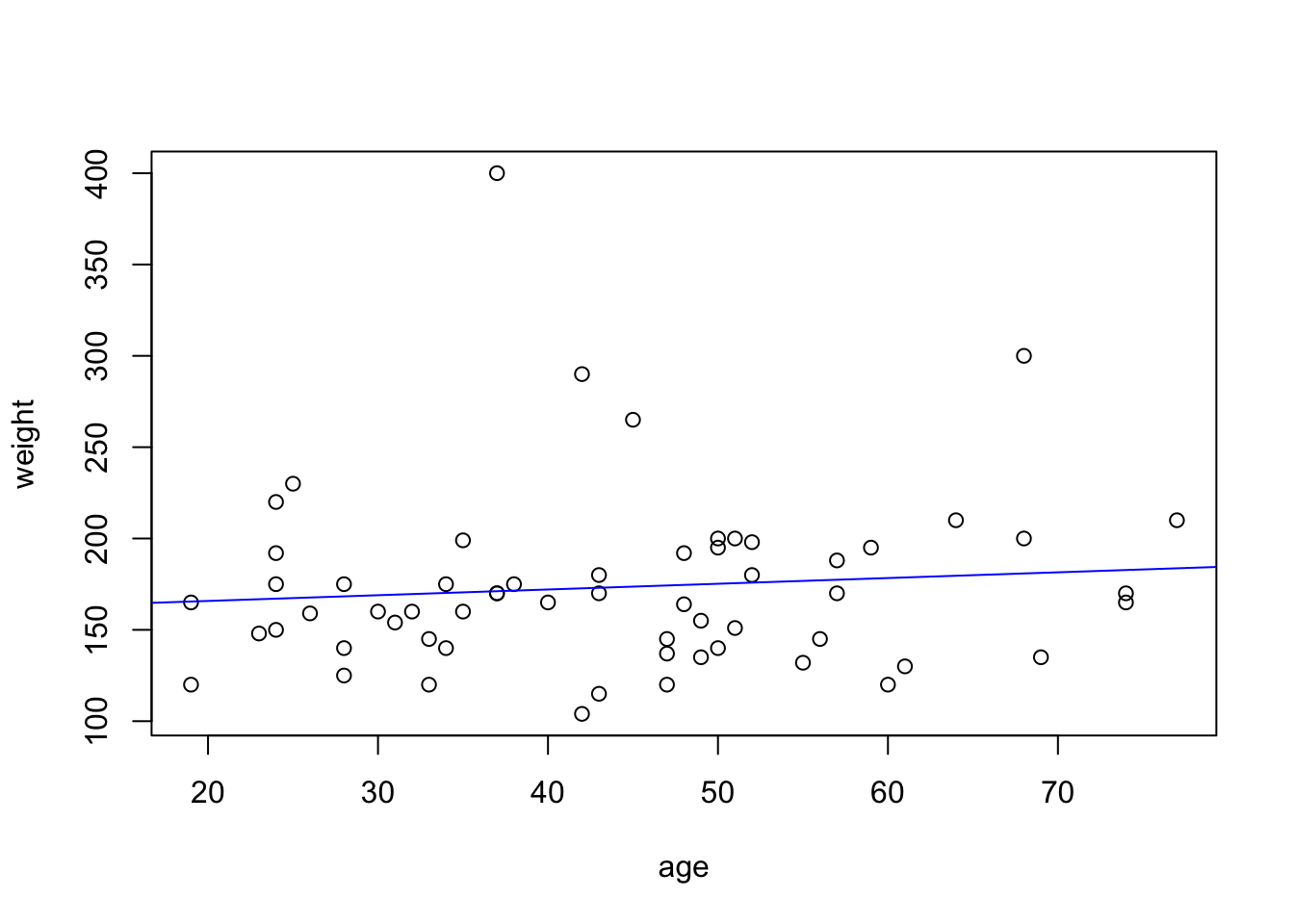
# visualizationplot(weight ~ age, data = brfss)abline(coef =coef(fit), col ='blue')
[L10] Do the data provide evidence of an association between age and weight (at the 5% level)?
Solution
The data provide no evidence of a relationship between mean weight and age (T = 0.727 on 58 df, p = 0.47).
[L10] What proportion of weight variation is explained by age?
Solution
Age explains an estimated 0.9% of variation in weight.
[L10] Construct a 95% confidence interval for the change in mean weight associated with aging one year.
Solution
The interval is:
\[
\hat{\beta}_1 \pm 2\times SE\left(\hat{\beta}_1\right)
\] The estimate and standard error are shown in the output above: